File Chunk Deduplication
The Merkle Tree optimizations we've talked about so far make adding and committing snapshots of the directory structure to Oxen snappy. The remainder of the storage cost is at the individual leaf nodes of the tree. We want Oxen to be efficient at storing many files as well as efficient at storing large files. In our context these large files may be data frames of parquet, arrow, jsonl, csv, etc.
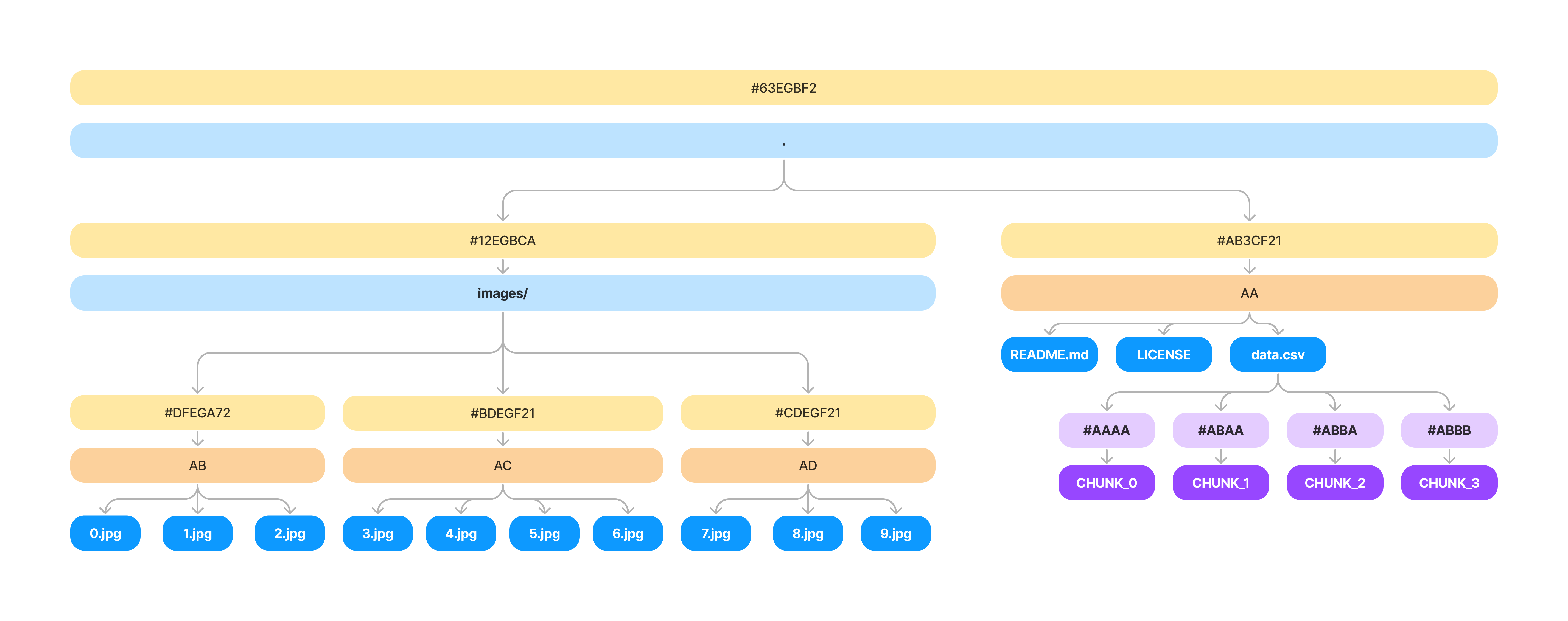
To visualize how much storage space individual nodes take, let's look at a large CSV in the .oxen/versions directory. The pointers and hashes within the tree itself are relatively small, but the file contents themselves are large.
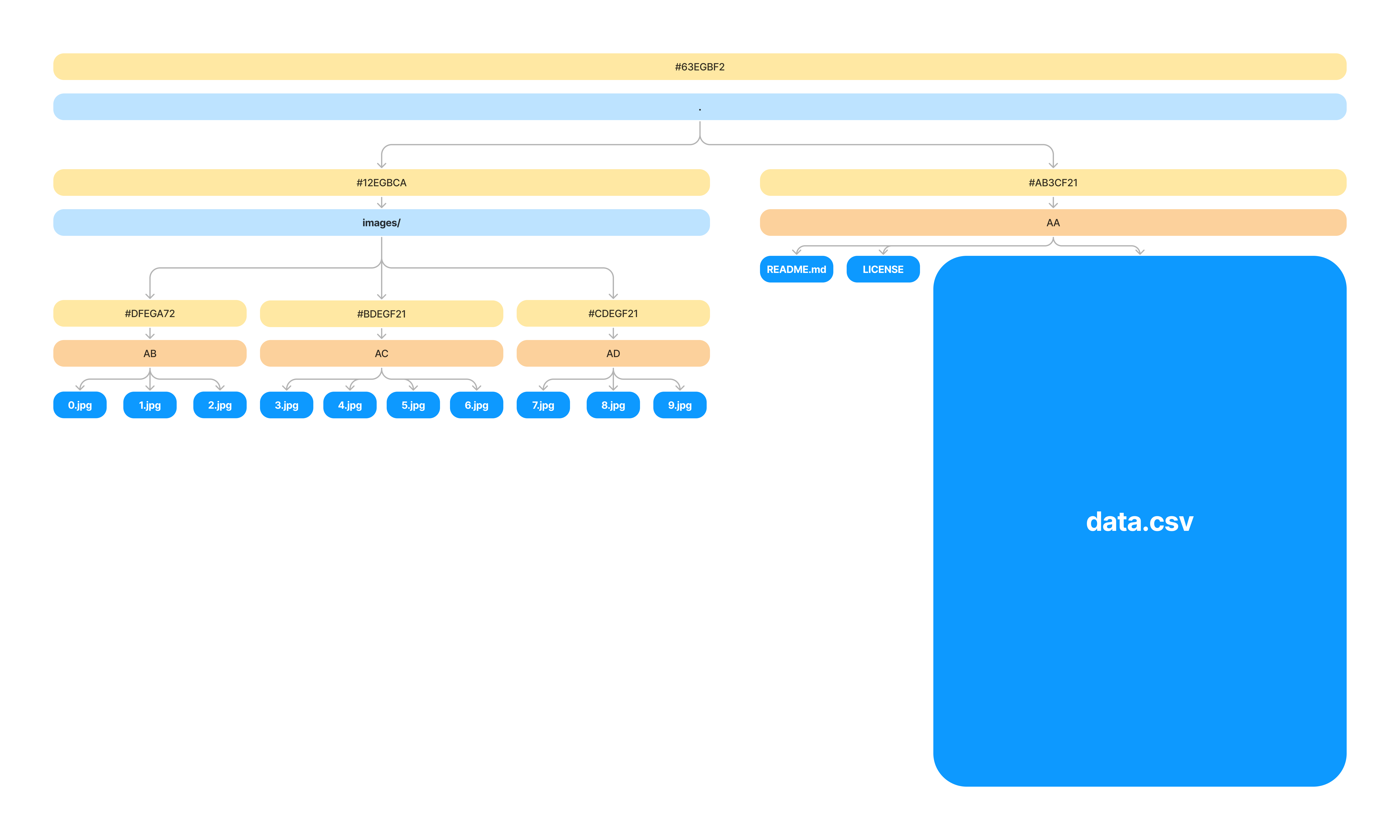
Remember, so far each time you make a commit, we make an entire copy of the file contents itself and put it into the .oxen/versions directory under it's hash.
This can be a problem if we keep updating the same file over over and over again. Five small changes to a 1GB file will result in 5GB of storage.
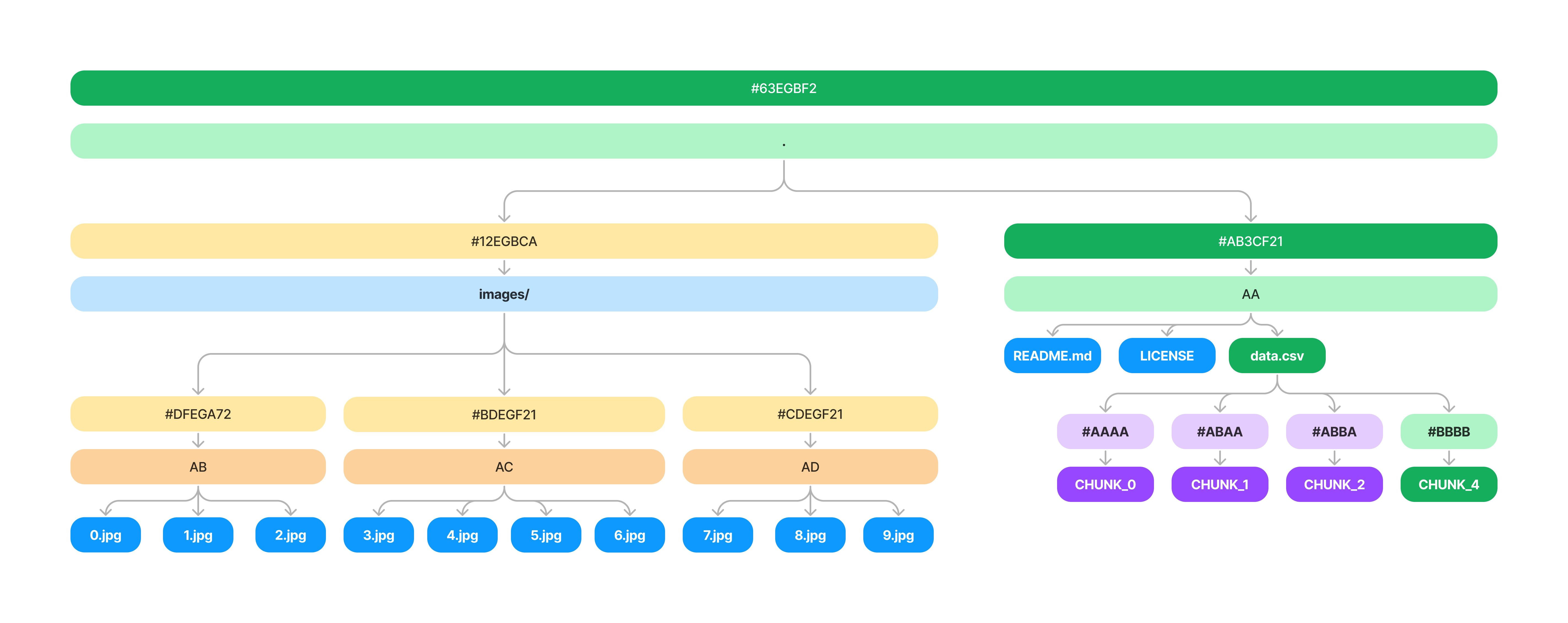
Think back to the key insight that we made earlier about duplicating data between versions of our tree. The same thing applies to large files. For example - what if you are editing and committing a CSV file one row at a time.
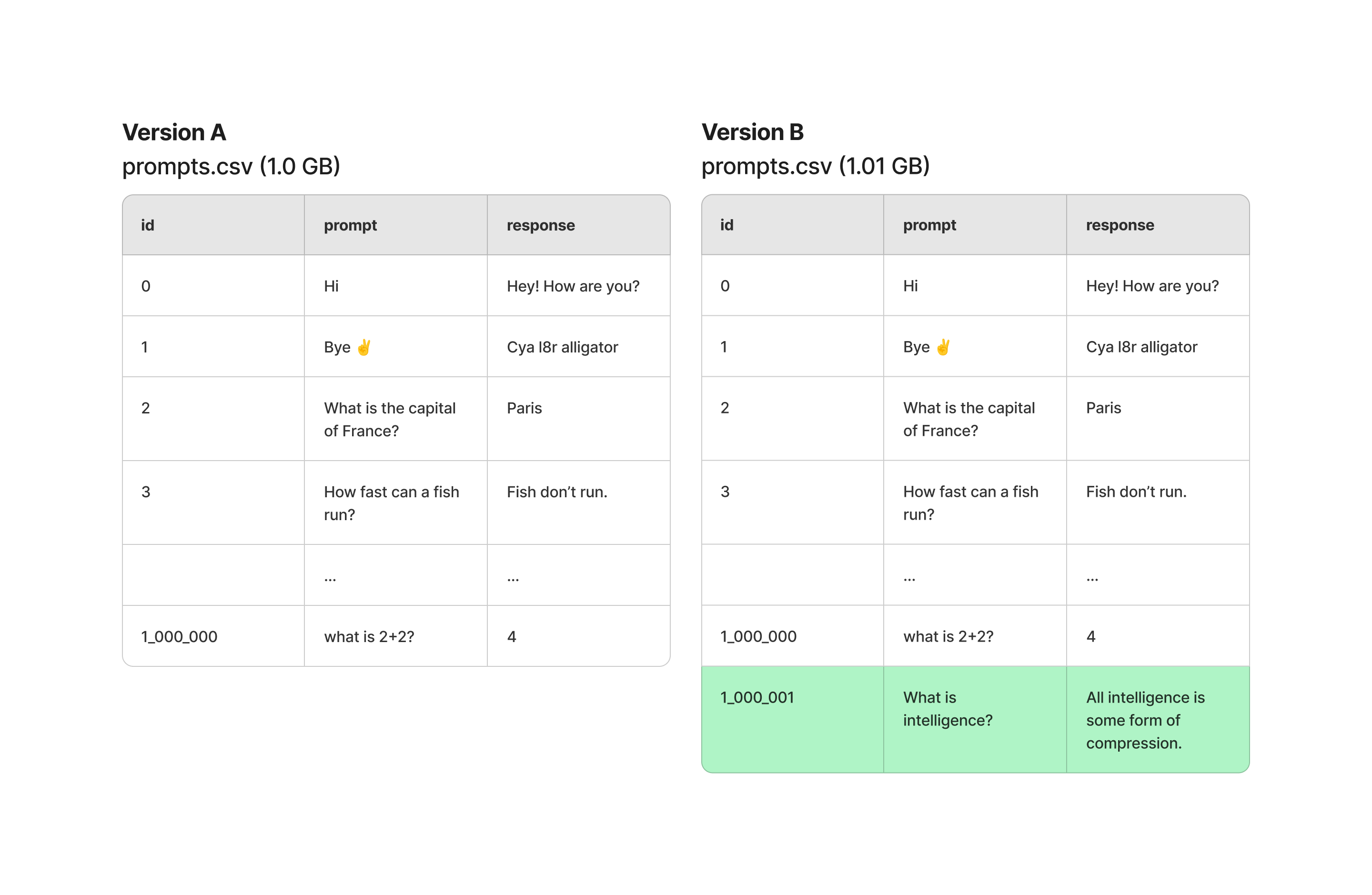
This results in a lot of duplicated data. In fact rows 0-1,000,000 are all the same between Version A and Version B.
To combat this, Oxen uses a technique called file chunk deduplication. Instead of duplicating the entire raw file in the .oxen/versions directory, we can break the file into "chunks" then store these chunks in a content addressable manner.
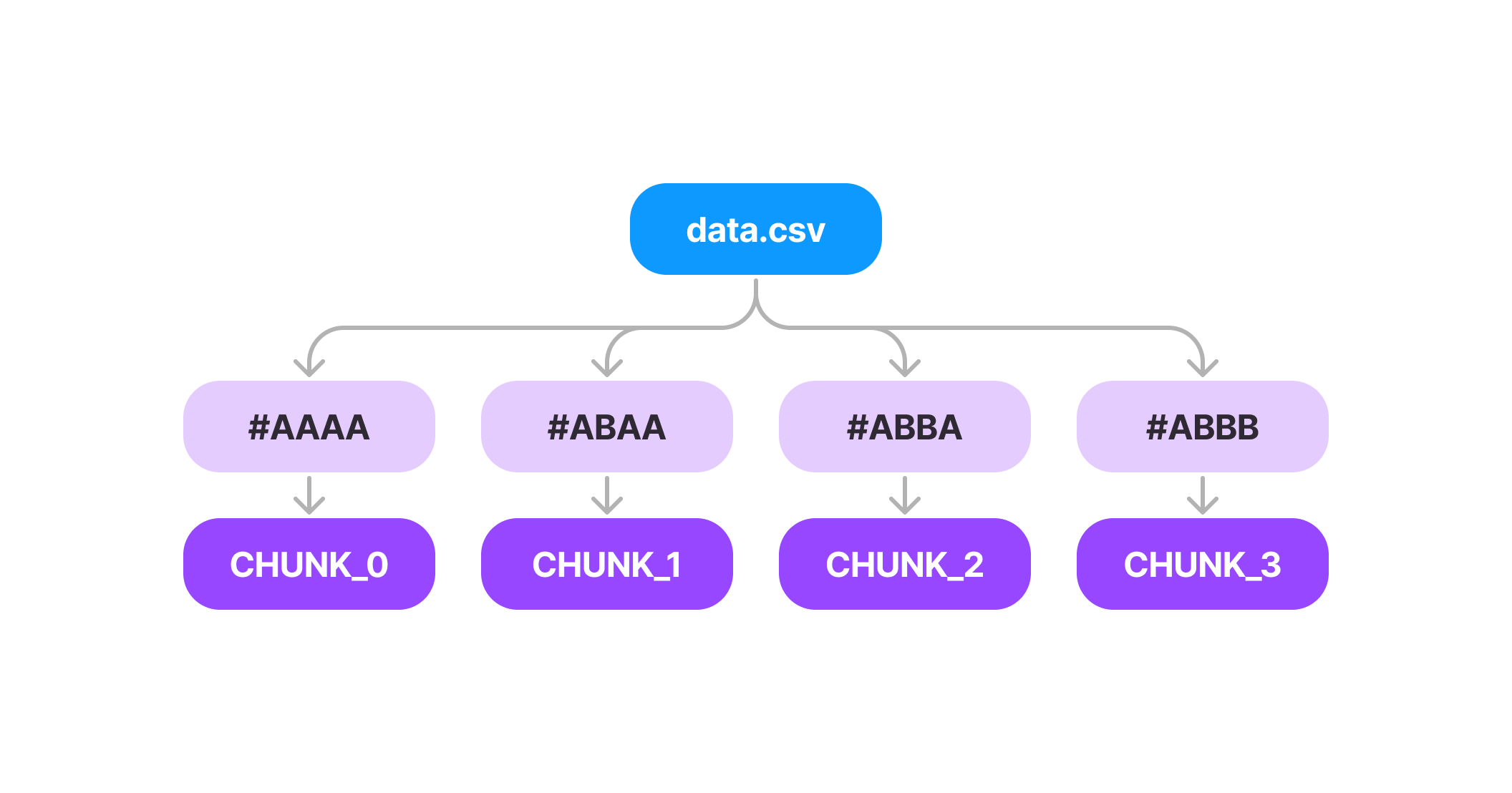
Then if you update any rows in the file, we create a new chunk for that section and update the leaf nodes of the tree.
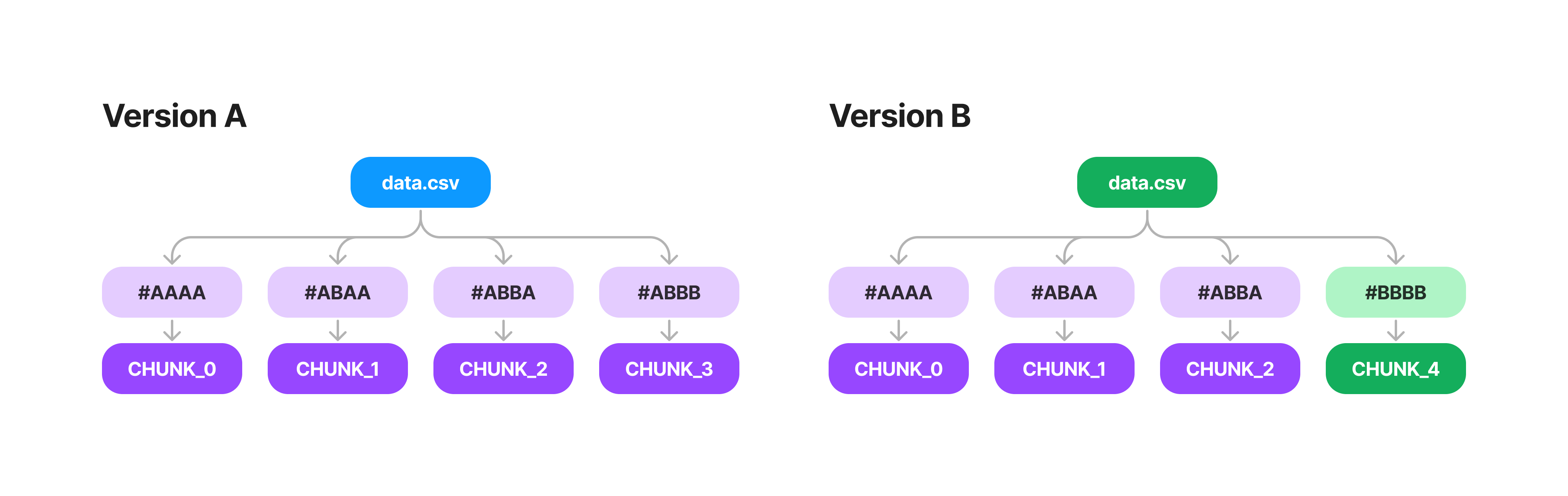
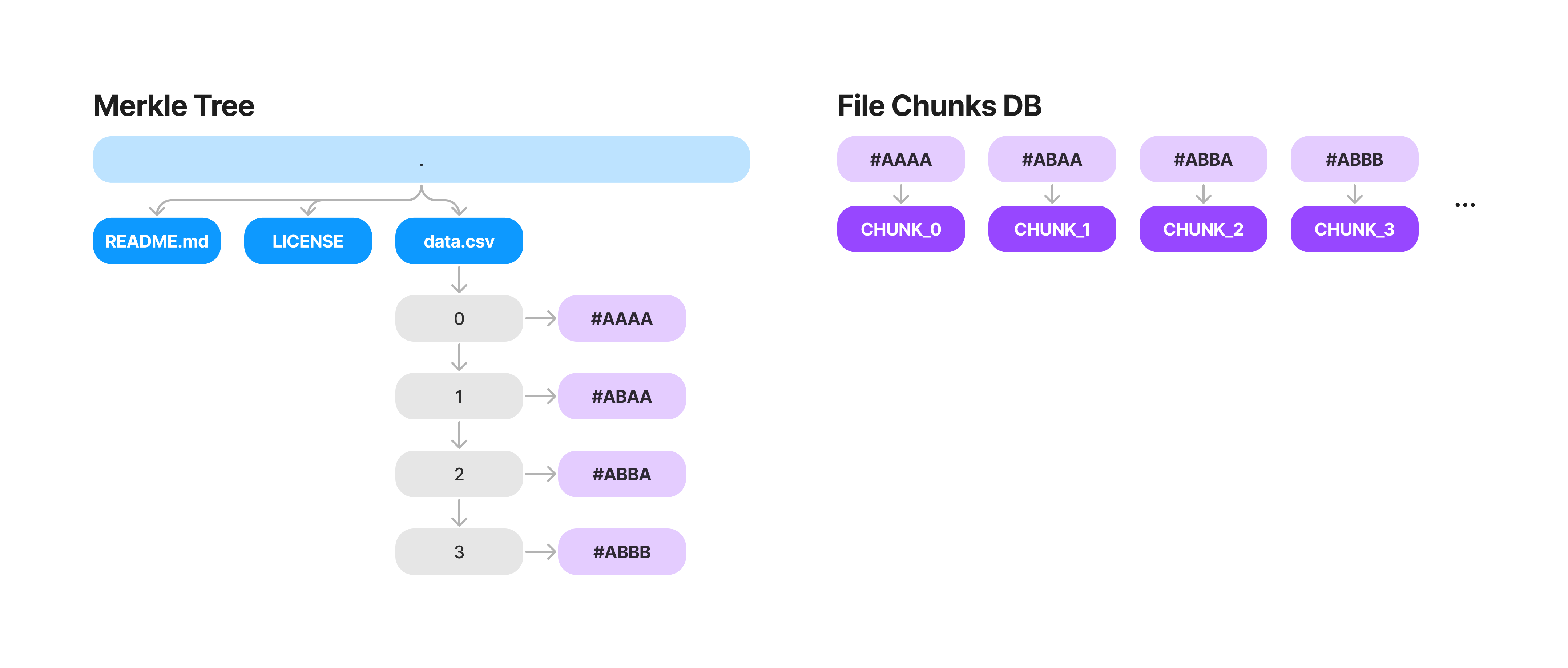
So the original tree looks like this.
Then when the row is added, all we have to do is update the final chunk and propagate the changes up the tree.
What's great about this, is now we also only need to sync the chunks that have changed over the network and not the entire file. Chunks themselves are ~16kb in size, so updating a single value in a 1GB file will only sync this small portion of the file.
When swapping between versions we simply reconstruct the chunks associated with each file and write them to disk. This means we need a small db that stores the mapping from chunk_idx -> chunk_hash. We can now store this in the .oxen/versions directory instead of the file contents.